
If you’re reading this, you’re probably the kind of person who’s attended a Big Data conference, and maybe find yourself sitting in on those “How to scale to your first x million users”. The problem is that in the real world, the problem isn’t so much scaling up from a prototype into production, but having enough horsepower to wrangle data in the conceptual phase, then scale down into a business application (then scale up again when customers want access to the raw data, but I’m getting ahead of myself.) As an industry, we’ve relied too heavily on borrowed-terms from architecture because the analogy breaks down when you consider that an architect doesn’t usually have to build first. Here, we’ll look at how Google’s BigQuery helped us do just that.
I’m writing this blog to share our experience in this “Scale first, build second” world, and to share our experience wrestling 7 years of telecom data for a client.
The Problem Statement
 company, with little thought of retaining them past a month or so. But, we knew the time would come when the customer would want/need the history, so we paid to store them in Amazon S3, which provided the rock-solid, ‘many nines’ availability we’d always wanted. But one day, the customer came to us with the classic ‘needle in the haystack’ problem: They wanted to be able to search for any record and get the results back in seconds. Actually, it wasn’t just that they wanted to search for records… The FBI was demanding that they perform a subpoena search for an active case, so failure (or even delays) were not an option. Our customer joked that we were the only thing keeping them from a ‘contempt of court’ order, so they were extremely interested in anything we could offer. Internally, we came to call this situation the ‘miracle of the FBI’ as one engineer noted, in a nod to Alan Rickman’s line as Hans Gruber in Die Hard. (Fans will recall that the bad guys could only open the vault once the FBI cut the power to the building!)
company, with little thought of retaining them past a month or so. But, we knew the time would come when the customer would want/need the history, so we paid to store them in Amazon S3, which provided the rock-solid, ‘many nines’ availability we’d always wanted. But one day, the customer came to us with the classic ‘needle in the haystack’ problem: They wanted to be able to search for any record and get the results back in seconds. Actually, it wasn’t just that they wanted to search for records… The FBI was demanding that they perform a subpoena search for an active case, so failure (or even delays) were not an option. Our customer joked that we were the only thing keeping them from a ‘contempt of court’ order, so they were extremely interested in anything we could offer. Internally, we came to call this situation the ‘miracle of the FBI’ as one engineer noted, in a nod to Alan Rickman’s line as Hans Gruber in Die Hard. (Fans will recall that the bad guys could only open the vault once the FBI cut the power to the building!)
We’d been in this space for years, but this particular problem posed all sorts of challenges, including:
- We knew enough not to throw away the original binary files (that all needed proprietary decoding to make any sense of), but we weren’t use to having to ‘decode twice’, which inevitably happens when users change their mind about which fields they want to search on.
- We’d grown used to running and maintaining our own, in-house, Hadoop clusters and even to renting Google and AWS’s flavors of them, but none of those provided the <1 minute response time our customers were expecting. We could spin those massive clusters up and get them what they wanted, but not without injecting our most senior resources (read: expensive) and not without incurring delays. The customer was always left wanting more.
- We knew that providing fast search capability alone wouldn’t get us to where we wanted to be, but we didn’t have the cycles to move up the analytics food chain. So, while we were working on the ‘search problem’, we were notably not working on those problems for which we had unique insights, like: “What causes churn?”, “Are my customers happy?”, “Which pool of customers are most likely to upgrade/leave/etc?”
So, as we plotted out the number of files by month that we had to process, we realized we were looking at about 7 million files that would have to be processed (and later, we found out, reprocessed). Each file contained approximately 10K calls, and weighed in at about 3Mb, so in the end we’d be trying to search through roughly 70 Billion events, over and over and over again.
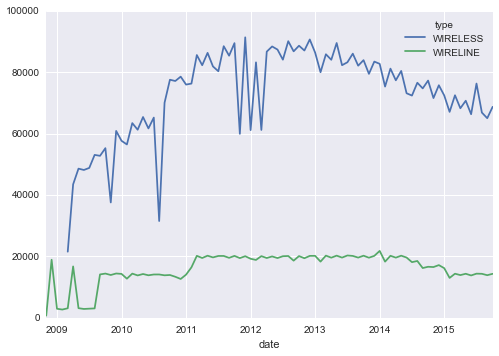
Our first job was to turn the binary files into something a database could handle. I could go into great detail on each of these, but suffice it to say we became intimately familiar with each of these approaches:
- Spinning up EC2 / GCC Linux instances, and rolling our own shell scripts to spread the load around, with each instance sniffing at a queuing service to poll a file from S3/GS, process and dump the data in another bucket.
- Doing the ‘MapReduce’ version of #1, where you try and line up your work in a ‘cat file | mapper | reducer’ UNIX pipe flow, and hope for the best…
We also tried a few things that, if I told you about them you’d stop reading, so I won’t… The point is that we needed to do all of these things for anything that was-to-be-considered a minimally-viable-product. I’ll emphasize that again. We weren’t hoping to scale up to 70 Billion events, we knew that our very first demonstration would have to show that capability. If we later got the business, we’d have other ‘production scaling problems’, but none of them would have to do with the data processing layer. (Again, note the failed borrowed terms from architecture: We weren’t building a ‘model’ so much as a fully-working database layer. This point is too often lost when thinking about BigData. When real estate developers like Donald Trump start building full-sizebuildings before they sell the concept to a buyer, then I’ll tune back in. Take that analogy one step further. When they build several buildings, then destroy all but the ones a customer wants, we’ll be back in the business of using the same language)
We were so desperate for a breakthrough that we pounced on the opportunity to be part of AWS’ early Lambda initiatives. Suffice it to say, AWS CTO’s Werner Vogels was fed correct information from early users, and developers of all stripes should get familiar with the scale, simplicity and economics of event-driven computing. Not surprisingly, Google is right on their heels with their own version, Cloud Functions, currently in beta. Both products do a superb job of separating you from the bare iron of instances and allow you to focus on your code. The shared economic benefits to you and AWS/Google are clear: Your code runs on whichever server is available at that moment but you forgo the ability to ssh into the box. In return, you’re now in the world of ‘event driven processing’, where the simple act of sending a file to S3 (or Google Storage) initiates as many self-contained functions (deserializing binary files, in our case) as you need.
Toying with BigQuery
But, if you’ve followed along this far, you’re wondering how all this database will be put into a database layer. Here again, we evaluated all of the offerings out there, and came to rest on Google’s BigQuery. It’s a joy to work with, a masterpiece of technology that cuts through your data quickly. I’m amazed that no one else as even seriously attempted this “SQL as a service” before. There are some interesting threads out there comparing BQ to some of the competitors out there, but it was our impression that nothing could hold a candle to BQ. Sure, you could learn about Redshift over at AWS, but you’d need to spin up more than a few nodes while you fiddled with data. We also thought that AWS’ Aurora offering was pretty cool because it was pretty fast and managed to impersonate a MySQL server so effectively, you could just port over applications that relied on those pesky MySQLy things like indices, triggers and procedures.
To save money, you’d find yourself turning them up and down all the time, and then you’d learn about vacuuming, and then you’d learn about … where was I headed with this line of thought? Oh yes, I was talking about staying on track! BQ helps you do that, because it lets you focus on what you are actually good at, rather than what you’ve been raised to think you need to master. Sure, you’ll never get to see Google’s source code, or ssh into a host, but is that really what you are in business to accomplish?
Anyhow, once our data was properly structured, and stored in BQ, we found running queries to be a breeze. In this case, we were searching for particular phone numbers over a particular date range. (As your costs are related to how much data you traverse, you always want to limit the search space when you can. )
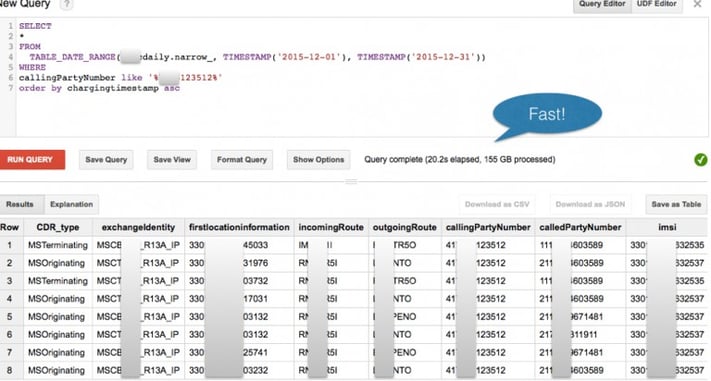
We decided that our best course of action was to process files using AWS’ Lambda service, and scoot over the processed files to Google Storage (GS), and then to load those files up into BigQuery. When we finally had our RawData_on_S3 → Lambda →ProcessedData_on_GS-> BQ operation set up (internally, we call this our “Conga Line”), we immediately got sideways looks from both our AWS and GCC account reps, asking us questions to the effect of “Why on earth do you use the other guy?”. Alas, it works and we continue to see both AWS’ Lambda and Google’s BQ as best-in-class, so it’s even worth it for us to pay the transfer fees out of AWS to get the job done. (We’re actively watching Google’s Cloud Function initiative – that could change the equation for us, since there’s generally a penalty to egress data from one cloud platform to another.)
Baking the BQ Backend Into Our Product
Once we knew we had stumbled on a workable tool, we had to figure out how best to ‘bake’ the BQ backend into our own workable product. The tool, in the end, had to be managed by us or our customer, had to have built in audit trails, and had to be self-serve from the end-user’s point of view. Fortunately, the various Google clients available (notably, java and python) work well enough once you figure how Google’s service accounts work. That allowed us to build our own front-end, that looks like this:
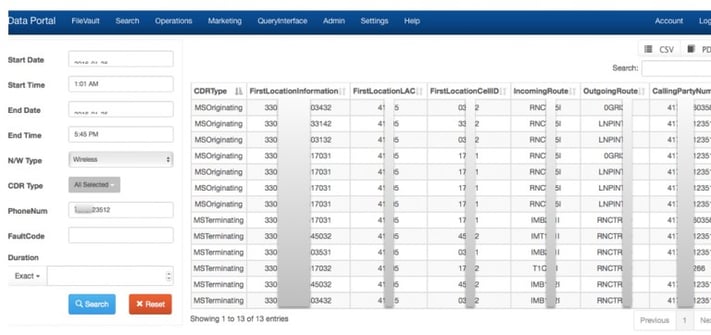
What this did is allow a host of new users, even those that don’t know SQL, to be able to seamlessly query the BQ tables. This was the ‘aha’ moment for us and our customers, because we had delivered fast, easy access to their data without the need for complicated backend database structures. It took a less than a week of this app being in production for more serious users to emerge, asking the kinds of questions that no GUI could ever answer. Those users wanted SQL queries to just work, and we built that for them too, bypassing the BQ query window that Google provides. (Interestingly, Google has seemed reluctant to let software developers just white-label the tool, but I found their product group to be quite helpful when asked…)
Where Do We Go From Here?
Rapidly returning SQL queries is great and all, but with this ‘freedom’ comes the challenge to ask better questions. That’s meant we’re turning our attention to the larger questions impacting Wireless carriers: What’s causing their customers to churn? Are there ‘social’ impacts at work? Does a customer’s perception of quality relate to what’s actually happening on the network? Can it be forecasted in some way? The picture below shows an individual’s network experience in a unique way — as a series of points plotted on a map, depicting successful/dropped calls by location — not just any location, but places that customer is likely to be.
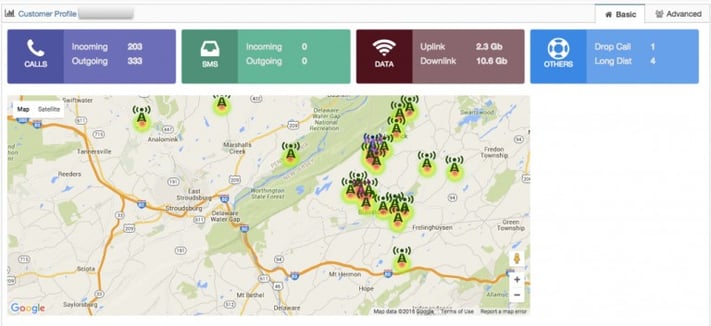
This is just the tip of the iceberg for us. Since I began writing this post, another challenge has landed in our laps. It seems that one of our customers is experiencing what’s called a ‘post dial delay’, or an (annoying) pause between the time they hit ‘send’ on their phones and the other end starts ringing. It’s subtle, annoying (adding up to months of ‘dead space time’ each day on the network) and tricky to track down. Enter BigQuery, where we can zero in on each record’s delay fields, and ask questions like:
- When did this start happening?
- Are there clusters of users experiencing this? (Are there clusters that are not?)
- Do the start times of this annoying behavior correlate with any new network elements going into the network?
Meanwhile, we’re also helping another customer move off a traditional MySQL setup that’s heavy on stored procedures and gets bound by I/O requests against the same table over and over. Our preliminary tests tell us that BQ’s new analytic functions will save a ridiculous amount of horsepower, and allow them to power down more than 20 hosts that are expensive to run and prone to problems.
Conclusions
All in all, it’s a great time to be watching AWS, Google, Microsoft and others battle it out for cloud supremacy. Independent software developers who harness these developments will come out ahead, while those who maintain a strict “I must own and maintain the whole stack” will lose out, because they’re not spending enough time in their area of expertise. Event-based-processing off of cloud-storage leading combined with massive ‘pay as you go’ databases like BigQuery are worth getting to know and embedding in your software solutions.