

Tell me if this story sounds familiar. You have an idea, a hunch, a theory that you'd like to 'flush' out. BUT, in order to do so, you need access to data from last month, maybe it's CDRs, billing data, smart meter data, etc. The emails, conference calls, and requests you'll have to make to get your hands on that data are daunting at best. But it's your data right? Why should you have to jump through so many hoops to get access to it? By the time you can even figure out who "owns" the data, you're onto the next task and your great idea is wasted, yet again.
Over the years, I can't tell you how many times the 'data access' issue has delayed or even completely stopped a project we've been involved with. Not because the idea didn't make sense or the business case didn't prove out, simply because getting the data from 'Point A' to 'Point B' was going to take too much time and effort. This is the definition of a 'data plumbing' issue. Big data tools are getting better, faster, cheaper, and more available every day. But the challenge of extracting and integrating data from a variety of sources has become an issue that organizations simply can't ignore. It's the ugly truth behind data analytics - it often takes more time and energy to extract, clean, and integrate the data than it takes to do the analytics itself.
Let's continue a bit with this 'data is like water' analogy. The water being carried down the pipes in your street doesn't do you any good if someone doesn't come and connect it to your house. Once it's connected to your house, you can do all kinds of things with it like cook, clean, shower, etc. - plus you can even SHARE the water with everyone else in the house. You never worry about about how sharing the water at home might slow down your access to the water (except when someone flushes while you're in the shower). OK I think you get the point. The same goes for the data at your company sitting on hard drives and servers in the back room. If you could only find a way to get the data flowing into your house (or big data tools), imagine the possibilities.
The typical deployment of our data analytics platform ESAP is split into 2 main phases:
- Data collection, deserialization, enrichment
- Data analytics, monitoring, alarming, GUI development
We often find that phase 1, 'data plumbing', can take just as much time (if not more) than phase 2. This drove us to realize that maybe each phase should be approached as its own project, and even offered as a separate service. Our CTO Peter Mueller recently published a blog about how open-source is reshaping our business and our customer needs. In that blog he touches on the fact that many of the smart folks at companies we work with nowadays are more open and willing to get their hands dirty in the data... if they can just get their hands on the data to begin with! We've also been hearing a lot more fear of being 'locked in' to a vendor solution that they can never take back in house. The data plumbing approach helps get the data in your hands with the option of using a vendor to do your analytics or doing them yourself... or even a mix of both.
Let's take a quick look at a real life example of our data plumbing services for a large telecom operator using Google's DataFlow and Pub/Sub services. The operator has a mix of landline switches (DMS, 5E), wireless switches (Ericsson), and long distance switches (DMS250, CS2K)... a fairly common blend of switches we see in North America. At the time we started the project, the data was being stored on large servers for short term, and external hard drives for long term. Queries on recent data took days and older data took weeks. A classic data plumbing issue. Here are the steps the data now goes through...
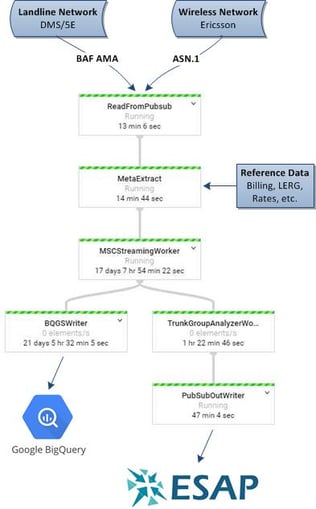
- A copy of all CDRs (landline, wireless, SMS, data, etc.) is sent to a pub/sub service that's always on and 'listening' for new data
- Next we deserialize the data by running proprietary software to convert the AMA and ASN.1 binary records to ASCII text
- Once everything is converted to text, we enrich each event record with data elements from sources such as the LERG, billing, rating, etc.
- The deserialized, cleaned, enriched records are then ready to be 'consumed' by any system or person downstream
- In this case, the data is sent to:
- Google BigQuery for unlimited ultra fast queries
- ATS' ESAP online dashboard with KPI monitoring and alarming
- Pub/Sub - which means anyone provided access can ingest the cleaned and enriched data to their own tool of choice without impacting performance on any other process/person using the same data (i.e. no one flushing the toilet when you're in the shower)
So, if you have lots of data flowing through your systems and want to tap into them yourself, next time call a 'plumber' (or contact us).